

 by
by Modern biology has more data than it can handle. Thanks to modern DNA sequencing, we now know the contents of genomes from thousands of people and thousands of species. The big challenge is making sense of it all. That’s where the Genetic Code comes in.
The genetic code is our first, best tool in making sense of it. In the 1960s a series of critical experiments set the stage for our current understanding of genetics and the genomic age. Without those efforts to puzzle out the genetic code, we’d have no hope of understanding the complexity of genomes.
First, a little background and review for readers not as familiar with biology. The reason DNA is important is because it contains the information for making proteins. Proteins are what actually do everything in cells and in bodies. Proteins are chains of amino acids. There are 20 amino acids, which can be assembled in any order. But that order is critical to the function of the protein. Genes in DNA are first transcribed into a sequence of RNA: a messenger RNA. This is a necessary first step, but it’s relatively straight-forward. Both DNA and RNA use a similar set of four nitrogenous bases. Information in the base sequence of the messenger RNA must be “translated” into an amino acid sequence based on the genetic code. This needs to happen correctly, or… Well, at best, the cell wastes energy. At worst, it dies. Or kills the individual it’s a part of.
So this is pretty important.
By the early 1960s, people had figured out most the story as I just described it. We understood the structure of DNA. We knew messenger RNAs acted as intermediates. And we knew that translation to form a protein happened at tiny molecular machines called ribosomes. Amino acids started out attached to a different kind of RNA, called transfer RNA. At that time, all these components could be isolated and combined under controlled conditions. It had also been reasoned that the code must consist of non-overlapping 3-base sequences, dubbed codons. (Three positions, each with four options, is the minimum number needed to specify one of 20 amino acids. 43 = 64. Two positions would not be enough, 42 = 16. Four positions would be overkill, 44 = 256.)
So how did the genetic code assign amino acids according to the base sequence in a messenger RNA?
The experiments that revealed this became possible when researchers were first able to synthesis artificial RNAs. They couldn’t yet control the sequence of bases. So how could they determine their order?
Genetics often feels like a puzzle. And in this case the solution was wonderfully simple. Start by using just one base. The first RNA was made of just uracil (U), one of the four bases in RNA. This artificial “messenger RNA” would consist of only one codon: UUU. It was combined with tRNAs charged with each of the 20 amino acids, ribosomes and the other necessary components for translation. The result was a protein consisting of only one amino acid, repeated over and over. The amino acid was phenylalanine. This was the first piece of the puzzle to be solved!

This trick could be repeated to find the other amino acids specified by all adenine (AAA), all cytosine (CCC) and all guanine (GGG): lysine, proline, and glycine, respectively.
In a way, those were the easy ones. Researchers still couldn’t control the order of bases in an artificial RNA. Again, the puzzle required a clever solution. Researchers realized they could mix two bases and get a protein that would contain all the amino acids specified by codons with all combinations of those bases. Alone that might not be very helpful, since it should cover about a quarter of the Code. But they reasoned that if they skewed the mix toward one base, say A, then they’d get mostly amino acids that favored A-rich codons. For example a mix of mostly A and some C gave proteins containing mostly lysine (already known to be encoded by AAA), asparagine, glutamine, and threonine. So these new amino acids most be specified by AAC, ACA, or CAA — Initially, it wasn’t clear which was which. But hey, this was progress! The reciprocal experiment, translating an RNA made from mostly C and some A (codons CCA, CAC, and ACC), resulted in addition of the amino acids histidine, threonine and proline (known from CCC). In this way, researchers made slow progress and built up their best guesses at the Code.

The next major advance came when synthetic chemistry allowed them to make short, specific RNA sequences. They were able to create an “oligonucleotide” of, at best, 4 bases. But these could then be enzymatically stitched together to make an artificial RNA. For example, they could create the RNA sequence UAUC, then ligate many together, making UAUCUAUCUAUCUAUCUAUCUAUC, etc. Under the experiment’s conditions, ribosomes would just start translation at the beginning of the RNA and read 3-base codons, oner after another, in same “reading frame”. This would produce a protein with amino acids in the order specified by those codons! In this case: UAU CUA UCU AUC UAU etc. The result? Tyrosine, leucine, serine, isoleucine, repeated over and over. This methods allowed unambiguous assignment of codons to amino acids.
Interestingly, some codons appeared to create only very short proteins. RNAs made from oligo GAUA, only ever had two amino acids. The sequence should create codons GAU AGA UAG AUA etc. The peptide (a short protein) consisted only of aspartate and arginine — so those were specified by GAU and AGA, but UAG appeared by cause translation to stop. It was the discovery of the first “stop codon”.
Ultimately all 64 codons were definitively assigned to amino acids, except for 3 stop codons that terminate translation. The result was the table below.
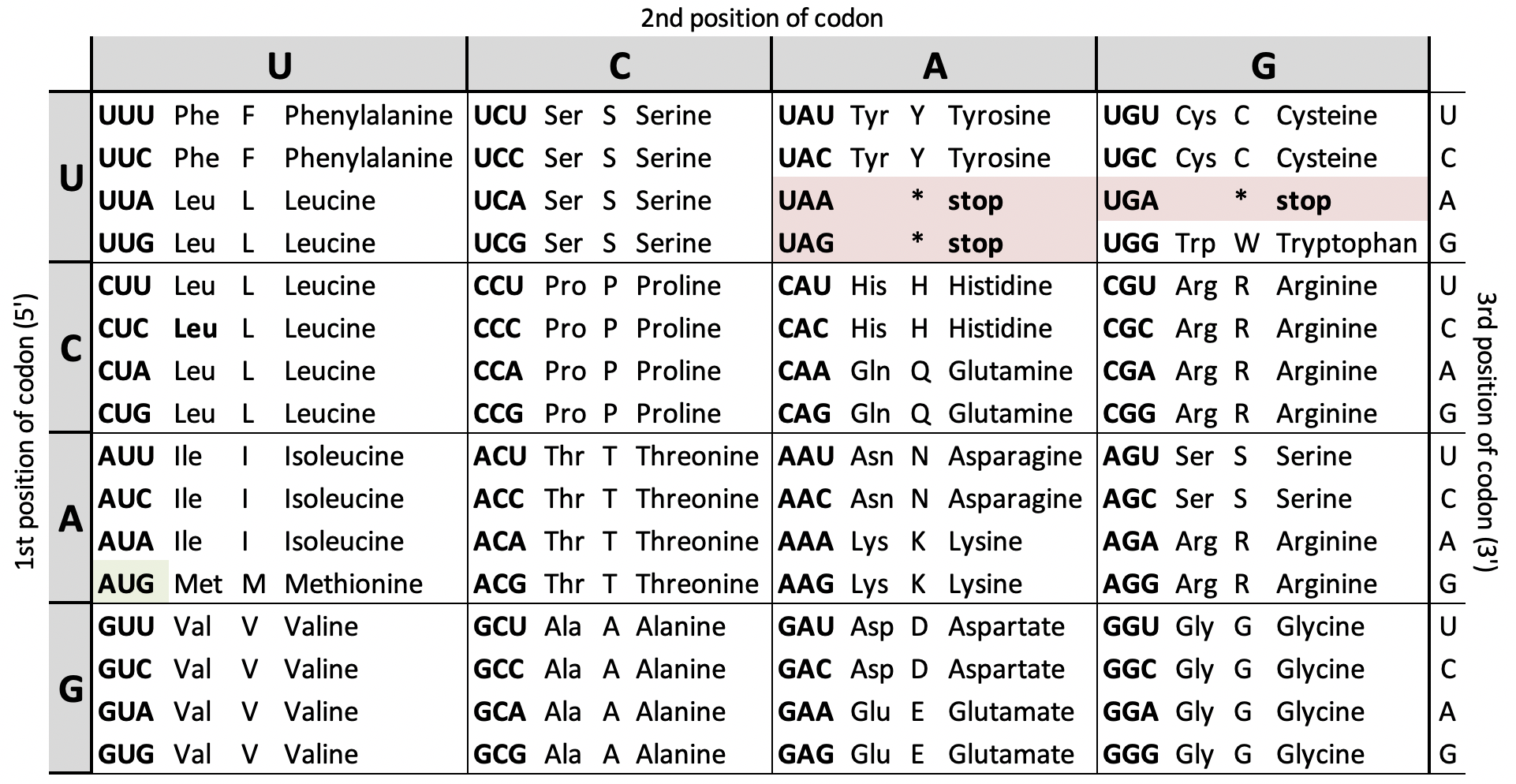
The Genetic Code is now used to decipher genomes, revealing where genes are located and the proteins they are used to create. While genetics and genomics have learned a lot and created new methods of analysis since the 1960s, the Genetic Code is still the first and most important tool to make sense of DNA sequence data. Since the 1980s when we routinely began sequencing DNA, biomedical science and related treatments have advanced profoundly. It is not unreasonable to say we are now healthier, life longer, and treat previously untreatable diseases by knowing life’s secrets encoded in this table. While the story of cracking the genetic code isn’t widely known among the public, it certainly deserves to be celebrated as one of the greatest achievements of science.
For more information, check out Life’s Greatest Secret: The Race to Crack the Genetic Code (2015) by Matthew Cobb.


